visual studio code のインテリセンスを自分好みに
はじめに
自分好みの補完機能が欲しくてVSCodeのインテリセンス機能を編集しました。
下記サイトを参考にしました。
実際にやったことは、
VSCodeをSQLエディタとして使う際、
テーブル名とカラム名の保管機能を追加しました。
VScodeを開いて、
ファイル(Code) > 基本設定 > ユーザースニペット
でSQLを選択します。
このファイルを編集することにより、任意の補完機能を追加することができます。
ファイル形式はjsonです。
"テーブル名": { "prefix": "テーブル名", "body": [ "テーブル名.${1|カラム1,カラム2,カラム3|}," ], "description": "説明" },
prefixに補完する文字、
bodyに補完する内容、
ここでは、テーブル名が打ち込まれると、
テーブル名+カラム1〜3のどれかを選択できるようにしています。
テーブル名がそれほど多くなければテーブル名ごとに上記を書いていけば良いかと思います。
VSCodeでデータベースに接続すれば、もっと色々とできることは増えるかと思うんですが、、、
諸事情によりそれはできませんので、しばらくこの方法を使っていこうかと思います。
仮想通貨のお勉強その2 APIから情報を引っ張ってくる
APIからティッカー情報を引っ張ってくる
下記サイトを参考にして(というかそのまま)、さわりだけ勉強、
https://qiita.com/ti-ginkgo/items/7e15bdac6618c07534be
requestsってライブラリは初めて使いました。
何するライブラリなの?
下記サイトを参考にさせてもらいました。
Requests の使い方 (Python Library) - Qiita
httpライブラリらしいですね。使いやすそう。
ティッカー情報をgetします。
import requests import json from pandas import DataFrame URL = 'https://coincheck.com/api/ticker' coincheck = requests.get(URL).json() #json形式のデータから、keyとlistを引っ張ってくる、 #さらにデータ形式を揃えて見やすい形に直します。 for key, item in coincheck.items(): print("%-9s : %-10.9s " % (key, item))
以下別の方法、
http://soy-curd.hatenablog.com/entry/2017/05/06/013515
from coincheck import market m = market.Market() result = m.ticker() print(result)
昔のデータも引っ張ってこれます。
import pandas as pd from datetime import datetime import matplotlib.pyplot as plt import matplotlib df = pd.read_csv("http://api.bitcoincharts.com/v1/trades.csv?symbol=coincheckJPY", header=None, parse_dates=True, date_parser=lambda x: datetime.fromtimestamp(float(x)), index_col='datetime', names=['datetime', 'price', 'amount']) df["price"].plot() plt.show()

ひっぱてきた情報をデータベースに保存できれば、良さげ、
データベースの勉強もしないと
仮想通貨のお勉強
仮想通貨
世の中流行ってますね。
冬休みでまとまった時間があったので勉強してみました。
色んなブログやら書籍やらありますが、主に下記を読みました。
結構ボリュームがあるので、大枠しか読んでませんが、、、
わからないことは、いろいろググりながら読み進めました。
https://www.bitcoinbook.info/translations/ja/book.pdf
ブロックチェーンやらマイニングってなんですかね、
・ブロックチェーンって何?
複数の取引(トランザクション)がまとまって1個のブロックになっており、
複数のブロックが鎖上に繋がっている。
ブロックの中身は下記図の通り、
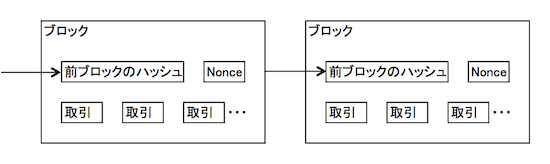
トランザクション以外にも、前ブロックのハッシュ値やnonceで構成されている。
Bitcoin等の仮想通貨は、ウォレットというものは、このブロックごとの取引情報をかき集めて、合計金額とします。
実際に一つのストレージに個人のお金情報を集めているわけではにです。
なので、個人のお金はブロック毎に分散されて保存されています。
・マイニングって何すること?
ブロックチェーンにおける合意形成(売買の承認)の方法で、
マイナーと呼ばれる人たちが実施しています。
マイナーはマイニングの対価として、仮想通貨を得ます。
流れとしては、
P2Pネットワークを伝わってくるトランザクション情報を、
マイナーはローカルのデータプールにいくつか集め、それらを加工することにより新規ブロックにして、
最後にチェーンにつなげます。
チェーンに繋いだら、繋いだ事を別のマイナー達に伝えます。
別のマイナーは、これを承認します。
尚、トランザクションには優先順位(マイナーに支払われる手数料、取引時間等で決まる)があるので、
優先順位が低いものは次のブロックへ廻されます。
具体的にマイングとは、何をするかというと、
「トランザクション+nonce+前ブロックのハッシュ値」のハッシュ値が、
ある特定の値以下になるように、nonceを決めることです。
このnonceを決める(総当たり的に計算する)のがマイニングです。
「ある特定の値以下」の値は流動的で、
マイニングが10分程度になるように、調整されます。
マイニングは、コンピューターの性能に依存するので、
高性能のコンピュータならすぐ計算できるし、そうでなければ遅くなります。
kaggleに挑戦その5 過学習、学習不足の可視化
学習曲線
データセットに対してモデルが複雑すぎる場合、過学習する傾向があり汎化性能が落ちてしまう。
トレーニングデータをさらに集めると、過学習は抑えることができるが、データをさらに集めることはコストが非常に高い。
また、実はこれ以上データを集めても無駄ということもある。 そんなとき、学習曲線を使うことでデータを集めることに価値があるか、検証できる。

有名な過学習、学習不足の絵ですね。
過学習と、学習不足が丁度良いバランスの場合、
トレーニングデータセットから作成したモデルの精度と、
そのデータを(例えば)K分割交差検証で評価したモデルの精度が同程度になります。
逆にすでに同程度の場合、これ以上サンプル数を増やしても精度は上がらないですね。
精度を上げたい場合は、モデル自体を変えた方が良いことになります。
今回作成したモデルはどうなんでしょう、、、
import matplotlib.pyplot as plt
from sklearn.learning_curve import learning_curve
train_sizes,train_scores,valid_scores = learning_curve(estimator=forest,
X=X_train,
y=y_train,
train_sizes=np.linspace(0.1,1.0,10),
cv=10,
n_jobs=1)
train_mean = np.mean(train_scores,axis = 1)
test_mean = np.mean(valid_scores,axis=1)
plt.plot(train_sizes,train_mean)
plt.plot(train_sizes,test_mean)
plt.show()
過学習してますねー。
データ数増やしていけば、過学習を抑えることができるってことがわかります。
実際は、データ数を増やすことはできないので、
モデルの複雑さを抑えて汎化性能を上げる必要があるかと思います。
kaggleに挑戦その4 k分割交差検証(k-fold cross-validation)及びグリッドサーチ
k分割交差検証
前回までで、ランダムフォレストでモデル予測を実施しました。
今回は、k分割交差検証、グリッドサーチを用いてモデル性能の評価及びハイパーパラメータの修正を行います。
これにより、バイアス高、バリアンス高のバランスをとることができます。
ランダムフォレストで、モデル化してみましたが、これは汎化性能がどの程度あるのか、
k分割交差検証で調べます。
k分割交差検証とは、トレーニングデータをランダムにk個分割して、
そのうちk-1個をモデル予想に使い、残りの1個でそのモデルを予想し、
この手順をk回繰り返すことで、そのモデルの平均性能を評価するものです。
kをどの程度の値にすべきかは、もとのデータセットに依存します。
kの値でどう変わるかというと、、、
・kが大きいと、各トレーニングサブセットの値が似てきて、評価のバリアンス高(性能評価の結果が、テストデータに依存した形となりやすい。)となりやすい。
・kが小さいと、各トレーニングサブセットの値が違いすぎて、バイアス高となりモデルの正確な評価ができない(毎回違う評価結果となる)。
ということです。
今回は、k=5として実施していきます。
from sklearn.model_selection import KFold from sklearn import metrics from sklearn.metrics import accuracy_score K = 5 kf = KFold(n_splits=K, shuffle=True, random_state=1 ) score_train_tmp = 0 score_test_tmp = 0 X = x_train y = np.array(titanic_df_main_random_forest["Survived"]) for train_index,test_index in kf.split(X): X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] # トレーニングサブセットでモデル構築 forest.fit(X_train, y_train) # トレーニングサブセットでの予測値 pred_train = forest.predict(X_train) # トレーニングサブセットのaccuracy auccuracy = accuracy_score(pred_train, y_train) #トレーニングサブセットのaccuracyを足していく score_train_tmp+=auccuracy #テストサブセットの予測値 pred_test = forest.predict(X_test) #テストサブセットのaccuracy auccuracy = accuracy_score(pred_test, y_test) #テストサブセットのaccuracyを足していく score_test_tmp+=auccuracy
これで、ランダムフォレストモデル(n_estimators = 100)の平均性能を評価することができます。
続いて、nn_estimators を変えたら、モデル性能はどのように変わるか、グリッドサーチ及びk分割交差検証を実施していきます。
グリッドサーチ
事前に決めるべきパラメータのことをハイパーパラメーターといいます。
今回は、2分木の数(n_estimators)がそれに当たります。
これはいくつにすれば良いのか???ということで今回はグリッドサーチを実施します。
グリッドサーチとは、パラメータを網羅的に変えながら、モデルの良し悪しを評価(例えばk分割交差検証)していき、
何が一番良いのか決める方法のことです。
scikit-learnには、もともとグリッドサーチ用のクラスが準備されているのでそれを使います。
(for文でループ!とかやらなくてもOK)
from sklearn.model_selection import GridSearchCV
param_grid = {"n_estimators":[10,20,30,40,50,60,70,80,90,100]}
tree_grid = GridSearchCV(estimator=forest,
param_grid = param_grid,
scoring="accuracy", #metrics
cv = K, #cross-validation
n_jobs =-1) #number of core
tree_grid.fit(X,y) #fit
tree_grid_best = tree_grid.best_estimator_ #best estimator
print("Best Model Parameter: ",tree_grid.best_params_)
print("Best Model Score : ",tree_grid.best_score_)実行した結果が以下です。n_estimatorsがいくつだと性能が良いかわかりますね。
Best Model Parameter: {'n_estimators': 90}
Best Model Score : 0.805836139169
kaggleに挑戦その3 ランダムフォレストを可視化
決定木の可視化
決定木の利点としては、意味解釈可能性があります。
ランダムフォレストで作成された決定木を可視化して、その意味を解釈しようと思います。
scikit-learnには、決定木を.dotファイルとしてエクスポートする機能があります。
その前に、.dotファイルを使うために、自分のパソコンにGraphVizをインストールします。
pip install pydotplus brew install Graphviz
ランダムフォレストで作成された決定木を.dotファイルにエクスポートします。
#ランダムフォレストを作成 from sklearn.ensemble import RandomForestClassifier forest = RandomForestClassifier(criterion="entropy",n_estimators = 100) forest = forest.fit(x_train,y_train) #dotファイルを出力 from sklearn import tree for i,val in enumerate(forest.estimators_): tree.export_graphviz(forest.estimators_[i], out_file='tree_%d.dot'%i)
ファイルが出力されたら、コマンドライン上で.dotファイルを.pngファイルに変換します。
例として、最初の決定木をpngファイルにしてみます。
>dot -Tpng tree_0.dot -o tree.png
実際のファイルは以下です。
一番大事な変数は?
scikit-learnのfeature_importancesを使うことにより、重要は変数がわかります。
重要変数は各変数での分岐の際に、情報エントロピーの差分を各決定木で平均させて、求められます。
titanic_df_main_random_forest_df = titanic_df_main_random_forest.drop("Survived",axis = 1).columns importances_df = forest.feature_importances_ random_forest_df = pd.DataFrame({"変数":titanic_df_main_random_forest_df,"corr":importances_df}) random_forest_df= random_forest_df.sort_values(by = "corr",ascending=False) sns.barplot(x = "変数",y = "corr",data = random_forest_df)

一番重要な変数は、Ageのようですね。