jsonファイルと辞書型
JSONファイル
JSONファイルって何?
調べればすぐに出てきますけど(以下等参考)、
プログラムと人の両方が理解できる形式ってイメージです。
【Python入門】JSON形式データの扱い方 - Qiita
同じようなものにXMLとかあるけど、それよりも見やすい気がします。
visual studio codeで独自のスニペッツを作成しましたが、
そのルールを記載するファイルがjson形式でした。
データベースのテーブルとカラムが記載している表から、
json形式でスニペットを作成するスクリプトです。
辞書型を使うとすごい簡単にできました。
PATH = "データベースのテーブル、カラムが記載しているエクセルファイルのパス.xlsx" dframe = pd.read_excel(PATH,sheetname="Sheet2") list2 = {} text = "" dict={} for column in dframe.columns: list2[column] = dframe[column].dropna() for n in list2[column]: text = n + "," + text dict[column] = text import json file =open("ファイルのパス.json","w") json_dict2 = {} for key in dict.keys(): json_dict= {} json_dict["prefix"]=key json_dict["body"]= key + ".${1|" +dict[key] + "none|}" json_dict2[key] = json_dict json.dump(json_dict2,file)
pythonで動的に変数を作成したい(for文でloopまわして作成)
動的に変数を作成
pythonでつまずいたことがあったのでメモ
for文でloopさせて、動的に変数作成をしたかったんですよ。
その際に、引数もfor文で作成的なやつです。
間違った例↓
for n in dataframe.colums "data_{}".format(n) = dateframe[n]
これはダメでしたね。
.formatは文字列に変数を代入するという方式みたいですね。
やるとしたら、
[[dateframe[1],[dateframe[2],・・・・,datafarame[n]]
みたいに、リスト内リストか辞書型が良いみたいです。
list = [] #リスト for column in dframe.columns: list.append(dframe[column].dropna()) list2 = {} #辞書型 for column in dframe.columns: list2[column] = dframe[column].dropna()
リスト内リストだと引数が数字になるけど、
辞書型だと、引数に文字列が使えるので便利かな、
ちなみに下記を参考にすると、exec関数で解決できるっぽいですが、
変数となるタイミングの問題で推奨されていなよう。
Python - pythonでname0,name1,name2・・・のように変数を宣言したい|teratail
モジュール外から呼び出すと、想定外の動きしないとか、そういうバグ
具体例としては以下2つの違い
for i in range(3): code = 'name{} = {}'.format(i, 3 ** i) # 例として3のi乗を代入 exec(code) print name0, name1, name2 # ==> 1 3 9
name1 = 123 def foo(num): exec('name{} = 456'.format(num)) print name1 # 123 foo(1)
visual studio code のインテリセンスを自分好みに
はじめに
自分好みの補完機能が欲しくてVSCodeのインテリセンス機能を編集しました。
下記サイトを参考にしました。
実際にやったことは、
VSCodeをSQLエディタとして使う際、
テーブル名とカラム名の保管機能を追加しました。
VScodeを開いて、
ファイル(Code) > 基本設定 > ユーザースニペット
でSQLを選択します。
このファイルを編集することにより、任意の補完機能を追加することができます。
ファイル形式はjsonです。
"テーブル名": { "prefix": "テーブル名", "body": [ "テーブル名.${1|カラム1,カラム2,カラム3|}," ], "description": "説明" },
prefixに補完する文字、
bodyに補完する内容、
ここでは、テーブル名が打ち込まれると、
テーブル名+カラム1〜3のどれかを選択できるようにしています。
テーブル名がそれほど多くなければテーブル名ごとに上記を書いていけば良いかと思います。
VSCodeでデータベースに接続すれば、もっと色々とできることは増えるかと思うんですが、、、
諸事情によりそれはできませんので、しばらくこの方法を使っていこうかと思います。
仮想通貨のお勉強その2 APIから情報を引っ張ってくる
APIからティッカー情報を引っ張ってくる
下記サイトを参考にして(というかそのまま)、さわりだけ勉強、
https://qiita.com/ti-ginkgo/items/7e15bdac6618c07534be
requestsってライブラリは初めて使いました。
何するライブラリなの?
下記サイトを参考にさせてもらいました。
Requests の使い方 (Python Library) - Qiita
httpライブラリらしいですね。使いやすそう。
ティッカー情報をgetします。
import requests import json from pandas import DataFrame URL = 'https://coincheck.com/api/ticker' coincheck = requests.get(URL).json() #json形式のデータから、keyとlistを引っ張ってくる、 #さらにデータ形式を揃えて見やすい形に直します。 for key, item in coincheck.items(): print("%-9s : %-10.9s " % (key, item))
以下別の方法、
http://soy-curd.hatenablog.com/entry/2017/05/06/013515
from coincheck import market m = market.Market() result = m.ticker() print(result)
昔のデータも引っ張ってこれます。
import pandas as pd from datetime import datetime import matplotlib.pyplot as plt import matplotlib df = pd.read_csv("http://api.bitcoincharts.com/v1/trades.csv?symbol=coincheckJPY", header=None, parse_dates=True, date_parser=lambda x: datetime.fromtimestamp(float(x)), index_col='datetime', names=['datetime', 'price', 'amount']) df["price"].plot() plt.show()

ひっぱてきた情報をデータベースに保存できれば、良さげ、
データベースの勉強もしないと
仮想通貨のお勉強
仮想通貨
世の中流行ってますね。
冬休みでまとまった時間があったので勉強してみました。
色んなブログやら書籍やらありますが、主に下記を読みました。
結構ボリュームがあるので、大枠しか読んでませんが、、、
わからないことは、いろいろググりながら読み進めました。
https://www.bitcoinbook.info/translations/ja/book.pdf
ブロックチェーンやらマイニングってなんですかね、
・ブロックチェーンって何?
複数の取引(トランザクション)がまとまって1個のブロックになっており、
複数のブロックが鎖上に繋がっている。
ブロックの中身は下記図の通り、
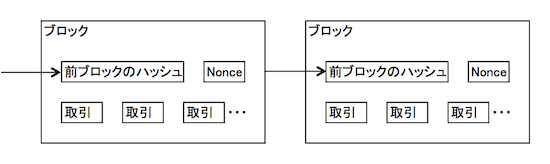
トランザクション以外にも、前ブロックのハッシュ値やnonceで構成されている。
Bitcoin等の仮想通貨は、ウォレットというものは、このブロックごとの取引情報をかき集めて、合計金額とします。
実際に一つのストレージに個人のお金情報を集めているわけではにです。
なので、個人のお金はブロック毎に分散されて保存されています。
・マイニングって何すること?
ブロックチェーンにおける合意形成(売買の承認)の方法で、
マイナーと呼ばれる人たちが実施しています。
マイナーはマイニングの対価として、仮想通貨を得ます。
流れとしては、
P2Pネットワークを伝わってくるトランザクション情報を、
マイナーはローカルのデータプールにいくつか集め、それらを加工することにより新規ブロックにして、
最後にチェーンにつなげます。
チェーンに繋いだら、繋いだ事を別のマイナー達に伝えます。
別のマイナーは、これを承認します。
尚、トランザクションには優先順位(マイナーに支払われる手数料、取引時間等で決まる)があるので、
優先順位が低いものは次のブロックへ廻されます。
具体的にマイングとは、何をするかというと、
「トランザクション+nonce+前ブロックのハッシュ値」のハッシュ値が、
ある特定の値以下になるように、nonceを決めることです。
このnonceを決める(総当たり的に計算する)のがマイニングです。
「ある特定の値以下」の値は流動的で、
マイニングが10分程度になるように、調整されます。
マイニングは、コンピューターの性能に依存するので、
高性能のコンピュータならすぐ計算できるし、そうでなければ遅くなります。
kaggleに挑戦その5 過学習、学習不足の可視化
学習曲線
データセットに対してモデルが複雑すぎる場合、過学習する傾向があり汎化性能が落ちてしまう。
トレーニングデータをさらに集めると、過学習は抑えることができるが、データをさらに集めることはコストが非常に高い。
また、実はこれ以上データを集めても無駄ということもある。 そんなとき、学習曲線を使うことでデータを集めることに価値があるか、検証できる。

有名な過学習、学習不足の絵ですね。
過学習と、学習不足が丁度良いバランスの場合、
トレーニングデータセットから作成したモデルの精度と、
そのデータを(例えば)K分割交差検証で評価したモデルの精度が同程度になります。
逆にすでに同程度の場合、これ以上サンプル数を増やしても精度は上がらないですね。
精度を上げたい場合は、モデル自体を変えた方が良いことになります。
今回作成したモデルはどうなんでしょう、、、
import matplotlib.pyplot as plt
from sklearn.learning_curve import learning_curve
train_sizes,train_scores,valid_scores = learning_curve(estimator=forest,
X=X_train,
y=y_train,
train_sizes=np.linspace(0.1,1.0,10),
cv=10,
n_jobs=1)
train_mean = np.mean(train_scores,axis = 1)
test_mean = np.mean(valid_scores,axis=1)
plt.plot(train_sizes,train_mean)
plt.plot(train_sizes,test_mean)
plt.show()
過学習してますねー。
データ数増やしていけば、過学習を抑えることができるってことがわかります。
実際は、データ数を増やすことはできないので、
モデルの複雑さを抑えて汎化性能を上げる必要があるかと思います。